命題論理のシーケント自動計算機 - Tokenizer の実装
やりたいこと
シーケント計算自動化
形式手法を使えるようになりたいと思って何度か Alloy に取り組んでみましたが,根本的に数理論理学がわかっていないので,一旦数理論理学を勉強することにしました.
テキストは日本評論社の「情報科学における論理(小野 寛晰)」を使用しています.
読み進めていくうち,命題論理のシーケント計算を自動化できそうな気がしたので一度実装してみようと思い立ちました.調べていませんが,このようなプログラムは世の中いくらでもありそうな気がするので,オリジナリティは皆無だと思います.
論理学の勉強と,新しい言語の勉強も兼ねているので,あまり人に見せられるコードではなくなりそうな気がしていますが,とりあえず進めていこうと思います.
TypeScript の勉強
TypeScript が面白そうだなと思っただけです.
もともと業務で C# を使用しており,静的型付けが当たり前の世界で生きていたので,JavaScript を使うようになってかなり面食らいました.
そこに,TypeScript というのがあると知り,せっかくなので使えるように
なってみようと思った次第です.
なお,TypeScript を知ったきっかけは,JavaScript を業務で使うようになってからJavaScript の構文解析器を探したのがきっかけです.ある程度すでに書かれていた JavaScript のソースを読むのが面倒で,C# でいつも Doxygen でコード解析をしていたので JavaScript でもそういうツールが
ないか探したところ,Esprima というツールを見つけました.これが TypeScript で書かれていたというのが,TypeScript を知ったきっかけです(名前自体は何度も聞いたことがあったのですが…).
なお,Doxygen に相当するツールは結局見つかりませんでした…….
コード解析の勉強
仕事で一度,C# ベースでスクリプト言語を作ったことがありまして,その復習のためにコード解析のソースを TypeScript に焼き直してみようという意図があります.
いきなり参考
先に参考を書いておきます.
ここのブログは 100 億回読みました.インタプリタの記事以外も何度も参考にしています.
TypeScript での実装にあたって参考にしています.元が ECMAScript の構文解析ツールなので,JavaScript の勉強にもなり一石二鳥感があります.
どんなものを作りたいか
シーケント計算自動化
言語仕様
!, AND, OR, ->, |- などの記号と,A_1, B, P, Q などのリテラルの列を読み込み,それを証明しようというものです.
より正確には,
- 英字から始まり,英字,_, ^ からなる文字列をリテラルとする;
- ! は否定とする;
- AND は論理積とする;
- OR は論理和とする;
- -> は含意とする;
- |- は Turnstile とする;
- , (カンマ) は論理式の区切りとする
とし,あとは一般的なシーケントをこれらの記号を使って表した文字列をインプットにします.
インプットを受け取ったら,そのシーケントの証明図を出力します.
インプットの例:A_1 -> A_2, A_2 -> A_3, A_1 |- A_3
出力様式
Tokenizer の実装
トークンとは
トークンとは,コードの中でそれ以上分けられないような,意味のある単位を表します.例えば,C# で
int hoge = 12;と書いたら,'int', 'hoge', '=', '12', ';' という単位に分けられるはずです.これら一つ一つをトークンというようです.
ソースコード
途中の実装は,GitHub に公開しています.
適当に,PrpProver と名付けました.
実装方針
シーケントに相当する文字列を読み込んで,トークン化します.
トークン化にあたって考えないといけないのは,
- トークン化するにはどのように文字列を読み込むか?
- AND や OR, -> などを予約語として抽出できるか?
- 予約語でない文字列(例えば ANDY)をリテラルとして抽出できるか?
あたりでしょう.
実装方針としては,簡単に述べると以下のようになります.詳しい説明はあとに続きます.
トークン化するにはどのように文字列を読み込むか?
与えられた文字列を一文字目から順番に読み込んでいきます.例えば,'!' という記号が来たら,否定の記号のトークンを発行します.'->' のような二文字の予約語もあるので,一文字だけではなく常に二文字を読み取れる仕組みが必要です.
AND や OR, -> などを予約語として抽出できるか?
予約語でない文字列(例えば ANDY)をリテラルとして抽出できるか?
与えられた文字列をトークンに区切ったときに,そのトークンの文字列が予約語に当たるかどうかを読み取ればいいのです.-> はリテラルとの混同は起こりえませんが,AND や OR はリテラルの定義ルールに当てはまる文字列ですので,AND や OR の場合は予約語,ANDY や ORG の場合はリテラルとして扱う必要があります.
抽象的なことばかり書きましたが,もう少し具体的に説明します.
文字列の読み込み
ここでは文字列の読み込みの流れを具体例を通して説明します.
意味のない文字列 '!(ANDY AND C_2) |- C_1' が与えられたとします.
目標は,'!', '(', 'A', 'AND', 'ANDY', ')', '|-', 'C_1' の合計 8 個のトークンを生成することです.
流れとしては,一文字目から順に文字列を読み込み,それが予約語に合致するか否かでトークンを
生成していきます.
現在読み込んでいる文字を currentChar, 一文字先の文字を nextChar とします.
- 1 文字目の読み込み
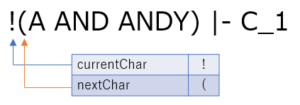
currentChar が '!' です.'!' は否定の予約語ですので,この時点で '!' のトークンを発行します.
- 2 文字目の読み込み
予め,文字列を読み進めておきます.

currentChar が '(' です. '(' は予約語ですので,この時点で '(' のトークンを発行します.
- 3 文字目の読み込み
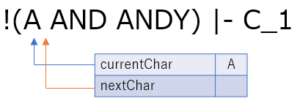
currentChar が 'A' です.これは予約語ではありません.
ここで何を行うかというと,文字列が途切れるまで(空白やカッコなどが出現するまで)の間,インプットの文字列を読み進めて文字列として抽出し続けます.
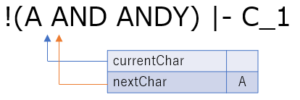
今の場合,一文字読みすすめると半角スペースによって文字列が途切れます.したがって,'A' がひとかたまりとみなされ,トークン化されます.
- 4 文字目の読み込み
3 番目で既に読み込まれており,半角スペースであることは分かっています.半角スペースはトークン化する必要がありませんので,半角スペースは読み飛ばします.
- 5 - 8 文字目の読み込み
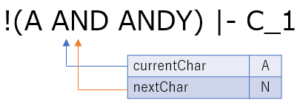
5 文字目は A です.手順 3 と同じく,文字が途切れるまで読み進めていきます.
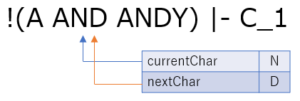
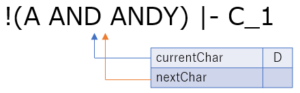
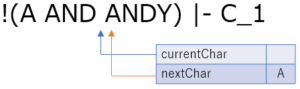
区切れました.ここまでで読み込んだ文字列は AND であり,これは予約語ですので,予約語のトークン AND を生成します.
- 9 - 13 文字目の読み込み
空白を読み飛ばして,ANDY の A まで来ました.ここもガンガン読み進めていきます.
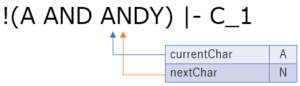
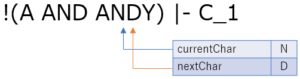
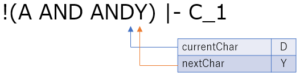
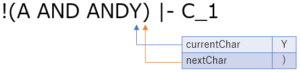
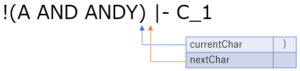
カッコが来たので 'ANDY' までがトークン化されます.
- 13 文字目
')' は予約後なのでトークン化します.
- 15 文字目
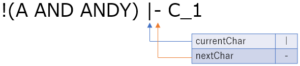
'|' は '|-' の一部です.次の文字が '-' であることが期待されます. したがって,nextToken が - であればトークン発行と読み進めを行い, そうでなければ Illegal トークンを発行します.
同様の方針で,'->' の実装も可能です.
- それ以降
それ以降も同様に,'C_1' が発行されます.
- 補足
文字列の読み終わりは,文字列の長さなどで判定します.
実装との対応
| 機能 | コード |
|---|---|
| 文字列読み取り機 | class Scanner |
| トークン化の本体 | Tokenizer.getNextToken() |
| AND, OR とリテラルの区別 | Tokenizer.readTokenModel() |
| 文字列判定 | Tokenizer.isLiteralStart, isLiteralPart() |
| 空白読み飛ばし | Tokenizer.skipWhiteSpace() |
これでトークン化ができるようになったので,命題論理式の AST や,それをシーケントとして保持する方法を次回以降で考えます.
以上!

コメント